Customising public information on the Internet
Electronic reference book about different life phases and life situations.
Written by Ivar Solheim (ivar.solheim@nr.no) and Per Myrseth (per.myrseth@nr.no)
to the 2nd International Congress on Electronic Media & Citizenship
in Information Society, 6-9 January 1999 Helsinki, Finland. Both authors work at the Norwegian Computing Centre
(www.nr.no).
Abstract
The basic goal of the projects described in this paper is to utilise the Internet to develop technological and
organisational solutions that make public information more accessible and customised. Focus on the need of the
citizens as they face different life situations and phases of life.
It is a fundamental problem that government information databases about important issues for the individual such
as tax, work issues, insurance, laws and regulations are organised in a fragmented way designed with little emphasis
on user friendliness and the actual needs of the citizens.
In Norway two projects have been established to meet these challenges. The central goal of the projects has been
to develop services on the Internet that provide public information customised to the receivers need. The projects
are called LivsIT and Mørelosen. LivsIT started in 1996, and is currently implemented as a pilot in four
municipalities. The Mørelosen service started fall 1997 and is currently in production. "LivsIT"
is literally an acronym of life situations and IT. The name Mørelosen means "the pilot to Møre",
where Møre is the name of the county responsible for the service. The two systems are quite similar, but
they use different technology to achieve their goals, and the target group is slightly different.
The projects are funded by the Norwegian Central Information Service and Møre and Romsdal county. The projects'
goal is to use modern information technology to collect, categorise and display customised information and make
it navigable according to the receivers need. The information is located in different sources, e.g. government
agencies, archives, brochures etc. For the citizen it is normally irrelevant which administrative agency or office
that is the source of the information, and the two solutions aims at providing seamless and relevant information
according to the request of the citizen. This may also imply that the information may contain supplementary information,
which the inhabitant had no knowledge about before the request.
The paper will present the background and discuss (i) the conceptual models of the two systems, (ii) use of metadata
and (iii) give examples from the services implemented in the two projects. Based on the knowledge we have gained
we also draft a possible solution for the next generation of this kind of information systems.
Problem: the fragmented and government centred character of public information
Norwegian citizens seeking information from both central and local government bodies and agencies are facing
two important problems; first, the information is often fragmented, and, secondly, the information is often structured
and presented in a government centred, not user centred way.
Seeking information from public administration and government agencies may often be a strenuous and demanding experience
for ordinary citizens. To obtain the relevant information you will most often have to know which agency is in charge
of the information. In many cases it is also a problem that the information offered by one agency or office only
covers a smaller part of the information the citizen seeks for. This means that e.g. a person who has recently
become unemployed will have to contact different agencies in order to get information about his/her current life
situation of unemployment. The person must contact the work agency for information about his rights as an unemployed
worker, the tax agency for information about his new tax, and the local government if he wants information about
local measures and organisations for the unemployed.
To citizens, offices in the local municipality are the natural starting-point to seek for help and information.
The fragmentation of administrative responsibility is confusing to the citizens, and it is not logical for an individual
trying to retrieve relevant information about different life situations. Examples of life situations are:
- getting married
- unemployment
- building a house
- establish a new company
For all these topics you will typically need information from different agencies and administrative bodies.
During the 90s the Internet has become an alternative public information channel to brochures, telephone and personal
contact. In Norway, almost all central public agencies and counties and municipalities have (in 1998) their own
web site. This reflects that Norway (and also the other Scandinavian countries) has relatively high Internet penetration,
by December 1998 about 30 % of all Norwegians are Internet users. The web site of the Norwegian Central Government
and Ministries, called ODIN, is the second most visited web site in Norway.
The problem of fragmentation is not solved by merely introducing a new technology. Both for government and the
citizens it is still a fundamental problem that government information databases about important issues for the
individual, such as tax, work issues, insurance, laws and regulations are organised in a fragmented way. It has
also too little emphasis on user friendliness and the actual needs of the citizens. The agencies or counties develop
all web sites in Norway, except ODIN. It is a problem with these web sites that they do not utilise the particular
possibilities offered by Internet to a more user centred approach to dispersion of public information. In stead,
the information is structured and presented in a bureaucratic way. This means that the information often is organised
according to governmental and bureaucratic needs, principles and organisational structure, e.g. based on legal
and administrative frameworks.
For example, when a person search for information about "marriage" he or she will have to know:
- which sites have any information about this and then visit these different web sites
- which department of the chosen agency has the administrative responsibility for "marriage"
- how to navigate in the chosen web site to find information about "marriage"
Ironically, to succeed in this search the most important condition is probably your own "bureaucratic competence".
This means that you in order to complete a successful search you will have to know a lot about the way government
hierarchies are organised and managed, and how to search for information from these hierarchies.
The challenge of the projects described in this paper have been this: How can the unique technological possibilities
of the Internet be utilised to develop holistic (not fragmented) and user centred (not government centred) concepts
and solutions for public information policies?
Introduction to the solutions
The Society Book (Norwegian: Samfunnsboka) was published in 1996. It was the first national attempt to make
a reference book about rules, rights and duties etc. in almost every life situation and topic (e.g. education,
health, labour market, traffic, environment, consumer rights etc). The Society Book also informs about which agency
to address and inquire in order to get the help we need. The structure of the book is based on life situations
and topics, and has an extensive index. Other countries, e.g. Denmark and Sweden, have developed similar reference
books.
In 1995- 1966 the need for an electronic reference book based on Internet technology was raised. In this paper
we will present the two projects and technical solutions, LivsIT and Mørelosen, which both follow the basic
structure of The Society Book. We believe that these two solutions are, at the time being, the most promising initiatives
in Norway.
Both these projects present public information from the central government (e.g. The Society Book), but in addition
public information both from the counties (regional level) and the municipalities (local government) is presented.
A basic idea in the projects is to make public information "seamless" which implies that the user does
not have to know if the information he is seeking is originally coming from "central", "regional"
or "local" sources - he just want his information!
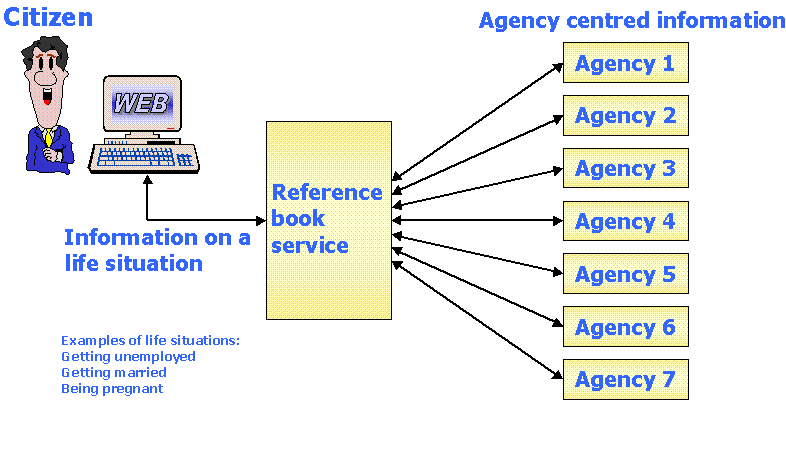
The two projects focus on different administrative levels. While LivsIT focuses on central, general information
combined with local information from the municipality, the Mørelosen project is developed as a tool for
a particular county. Mørelosen focuses on information from the county's administration.
Basic requirements to an electronic reference book about public information
A project with the goal of developing an electronic reference book will have to meet requirements both from
citizens and the publishers - and these may be quite different. From the citizen point of view, an electronic reference
book need to have at least the following characteristics
- easy to user
- easy to find what you are looking for
- the information has to be complete and correct
- the solution has to be based on open and well populated technology like WEB technology
- free of charge
From the information publishers point of view the service need to have the following characteristics:
- easy to deploy new information
- easy to update existing information
- easy to do version handling of information
- easy to delete information
- no need for a specific editor
- low technical knowledge needed to publish information
- low technical knowledge needed to maintain the system publishing the information
When it comes to copyright regarding public information it is obvious that information published in an electronic
reference book must be open and public available and it must be free of charge. It should also be clarified to
the user that neither a manual nor an electronic information service could guarantee completeness. With completeness
we mean that the service may not contain absolutely every piece of information relevant for a specific life situation.
LivsIT
The LivsIT solution has strong focus on life situations and the main target user group is service personnel
at the local municipality. Citizens are asking questions to personnel at the information counters, and the personnel
use the LivsIT solution as a tool to give service of high quality. The information suppliers are the county, central
government and public offices in the municipality itself. The LivsIT solution contains two levels of information
that can be used separately.
- specific local information (local government in the municipality)
- general information (municipality independent information, supplied by the county or central government.)
The second type of information should be the same at least within one county, and most of it will be the same
nation-wide. It is therefore of interest to establish a nation-wide service , which all municipalities can connect
to. The task of establishing such a solution involves politics and funding. A pilot version of the LivsIT system
has been introduced in four pilot municipalities and has been met with interest and enthusiasm from information
workers and others in these municipalities. Because of delays in preparing and organising the general, central
information the LivsIT system is still under development.
Entering information into LivsIT
The information is loaded into LivsIT by using a special client and it is stored in a database. By this client
you have to do the following steps:
- Enter an URL to the information source you wish to load
- associate the URL to a set of suitable predefined life situations
- associate the URL to a set of keywords
- associate the URL to a responsible agency, the information supplier
One important point about the structure of the LivsIT solution is that the local installation of LivsIT handles
the local loaded information, but it is configured to request other LivsIT resources for information. Both the
county and the central government are supposed to have similar LivsIT services running. Each installation of LivsIT
has the ability to pass on a request for information to other LivsIT installations.
Retrieving information from the system
The user interface in the LivsIT client is a Java applet mainly containing a hierarchical menu, which lists
approximately 200 predefined life situations. These life situations are grouped and it is also possible to do a
word search in the list of life situations. When a user choose one of these life situations, the client sends a
request for information to the LivsIT server, the server responds with a list which we call the response list.
It is a list containing all the available requested information sources. The user is then allowed to choose one
of the sources in the response list at a time. A user can make the response list narrower by combining a life situation
and one or both of the following:
- reducing the number of information suppliers by choosing the ones of interest
- reducing the number of index terms associated with the response list by choosing the ones of interest.
When a certain information source is chosen in the response list, the information requested would be presented
using ordinary WEB-presentation (this part of the presentation is not a part of the Java client). At the time being
the LivsIT service is based on Internet technology, but so far not open accessible from Internet. There are plans
for making at least municipality independent information, supplied by the county or central government accessible
from Internet.
The LivsIT user interface looks like this:
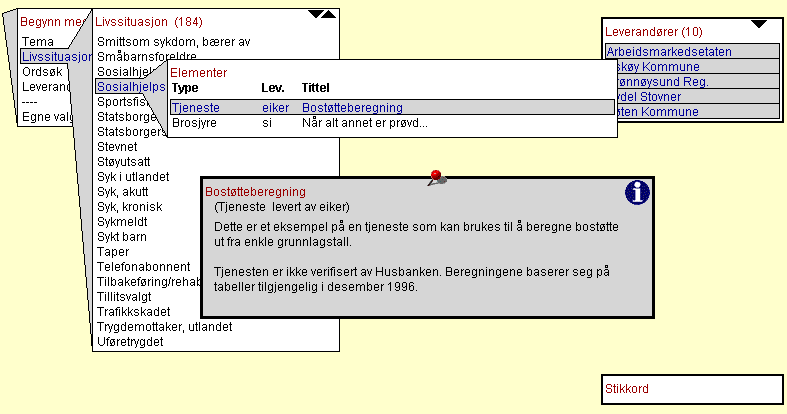
On the left-hand side on this screen shot you see the menu listing of a certain life situation and its response
list containing two elements. The elements are one of the type services and one of the type brochures. The active
element, the service, has an abstract. It is shown in the rectangle in the lower centre of the screen. The symbol
"i" on upper right hand corner of the rectangle is a link to a web-page showing further information regarding
this service. The list of information suppliers is shown on the upper right hand side of the screen.
The target group of LivsIT
The target group is as mentioned service personnel in local public offices. The idea is that these personnel
may use LivsIT as a basic tool in their information work for the public. Most of the information workers have used
Internet several times and have rudimentary knowledge about the Internet. This means that LivsIT has to meet ordinary
demands to a computer systems user interface and functionality.
The LivsIT project has been going on for several years already. During this time the project group has increased
its knowledge regarding both the users and the information suppliers needs and demands. This project has given
the involved actors the opportunity to co-operate in new ways. The project has established a network between actors
on different administative level.
Mørelosen
The Mørelosen solution focuses on life situations and topics basically like the structure in the "Society
Book". The name Mørelosen means "the pilot to Møre", where Møre is the name
of the county. Mørelosen is the name of an Internet publishing service and a tool offered by Møre
and Romsdal County. In this County there are 38 municipalities. Each of the municipalities can use Mørelosen
free of charge, both for publishing information and for retrieving information. Information accessible using Mørelosen
is available on Internet. Every public office in the county has been offered to use Mørelosen, and the response
so far is very positive.
Mørelosen is a tool primarily made to cover the county's internal need when giving different services. The
service is made accessible from Internet so it's an open information service to citizens, private and public sector.
Mørelosen is partly a new information service and partly a service linking different existing information
services together.
We will focus on the part of Mørelosen containing the Java based user interface, the document archive and
how these parts of Mørelosen are implemented.
Loading information into Mørelosen
Information is loaded into Mørelosen by making information available on a WEB-server either as an HTML
document or as a Word, Excel or PowerPoint document. The only restriction is that the document must contain metadata
and that the search engine used must accept the format type of the documents. By metadata we mean a tag like "[MLOS:01.03.15]".
This tag is located at the end of e.g. a Word document and it makes it possible to the search engine to categorise
the document accurately. The tag must be in accordance with a predefined archive structure made by the county.
Publishing information is done by two major steps:
- make the information available on Internet
- load documents into a searchable index
Comment to first step: The author (e.g. Ola Normann) of a certain document, e.g. hunting_regulations.doc, can
save the document in his catalogue on a fileserver on the Intranet, e.g: /Internet/department-x/Ola_Normann/hunting_regulations.doc
In the Møre and Romsdal county there has been made an automatic routine which copies files from a certain
part of the intranet, using ftp, to the main WEB-server at Mørelosen. This means that the author don't have
to care about copying his files to the WEB-server.
The search engine does the second step. The search engine scans those WEB-servers it has been told to scan. It
loads every document into a free-text searchable index. And that index will contain the tags e.g. "[MLOS:01.03.15]".
By having the possibility of directing the search engine where to go and where not to go, the system administrator
has a powerful tool to make sure that only relevant sources are included in Mørelosen.
Retrieving information from the system
The user interface in the Mørelosen client is a Java applet mainly containing a hierarchy menu, which
totally contains approximately 1400 predefined subjects and life situations. The top level of the hierarchy consist
of 25 main categories, each containing 3-4 levels of sub-menus. When a user choose one of these menu choices, the
client sends a request for information to the search engine, the search engine responds with a response list. It
is a list containing all the available requested information sources. The user is then allowed to choose one of
the sources in the response list at a time. In addition a user can make the response list narrower by combining
a certain menu choice and one or both of the following:
- choosing the information suppliers of interest
- add a free-text term in the same way as entering a free-text term in ordinary Internet search engines
When a certain information source is chosen in the response list, the information requested is presented using
ordinary WEB-presentation (this part of the presentation is not a part of the Java client). The Mørelosen
user interface looks like this:
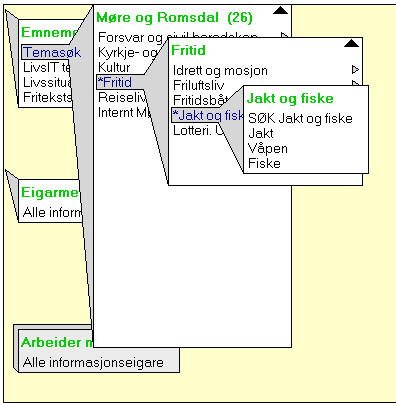
This screen shot from Mørelosen shows the menu item "Leisure" and its sub-menu "Hunting".
There is also a restriction on information from which information suppliers (e.g. only the department "landbruksavdlinga")
should be in the respons list.
Mørelosen response list, see figure below, is basically a response list similar to what AltaVista presents
on its Internet service.

Experience
A pilot version of the "LivsIT" system has been met with interest and enthusiasm both in the central
agencies involved in the project and in the co-operating municipalities. There is no doubt that Internet based
solutions which aim at customising public information is very promising and politically very interesting. The project
has also been mentioned by both ministers and other politicians in Norway as an example of how to utilise the Internet
to the benefit of the ordinary citizen.
A major obstacle to this kind of initiative is of political and organisational nature. A basic problem is how to
succeed in creating a fruitful and committed co-operation between different agencies and governmental bodies. Almost
all Internet projects within the public sector in Norway are initiated by and for the different agencies themselves.
In Norway Internet project in the e.g. tax, labour and insurance agencies have high priority. Projects involving
and demanding a high degree of co-operation with other governmental bodies and agencies do not have this high priority.
Nevertheless, the LivsIT project has established valuable and concrete co-operation with several central agencies,
particularly the National Insurance agency.
During the last few years approximately 3000 brochures have been published by the Norwegian Central Information
Service related to different subjects and life situations. Some parts of this information are already available
on Internet and in LivsIT. Further development and diffusion of LivsIT has been delayed because of delays in preparing,
organising and adjusting the necessary central information to the LivsIT system. This work is probably completed
in 1999.
The experience so far also indicates that it is important to experiment with different kinds of technical solutions
in order to rationalise and increase the efficiency of the process of integrating information in the LivsIT. The
processes of loading information into LivsIT is manual and very time consuming, but produce - on the other hand
- output from the system with very high quality. The Mørelosen project is of particular interest in this
connection, because this project uses a different technological approach when it comes to loading and indexing
information.
Next generation electronic reference book
Our experience tells us that the time-consuming and difficult work seems to be collecting and categorising information.
With that in mind we have started to look at next generation of electronic reference book.
In the next generation we want to apply the fields of pattern recognition and statistical modelling on text documents.
Our goal is to automate the process of categorising the collected information sources. We would like to compare
the text in information sources with a set of information sources viewed as basis documents. The basis documents
contain metadata and are therefor manually categorised according to a predefined archive structure. In this way
we can automate the process of categorising the information sources that does not contain metadata.
| |
Collecting information sources |
Categorising information sources |
| LivsIT |
Manual operation |
Manual operation |
| Mørelosen |
Automatic by use of search engine |
Manual operation, use of metadata |
| Next generation |
Automatic by use of search engine |
Automatic by use of metadata and pattern recognition |
The table above tells us that the next generation of reference book will according to our believes use search engine
or similar technology to collect possible information sources and it will use pattern recognition combined with
metadata to categorise the individual information source. When we use search engines as tool for collecting a set
of possible information sources many of the individual information sources will be found outside the scope of our
electronic reference book and they will be categorised as not relevant information sources. The others will be
categorised according to the predefined archive structure and loaded into the search engine index.
We also plan to use XML (eXtensible Markup Language) to achieve use of metadata and to make data and presentation
independent of each other.
Comparison of the reference books
We have tried to estimate based on our knowledge and experience a comparison of the tree solutions. The figure
below shows this comparison.
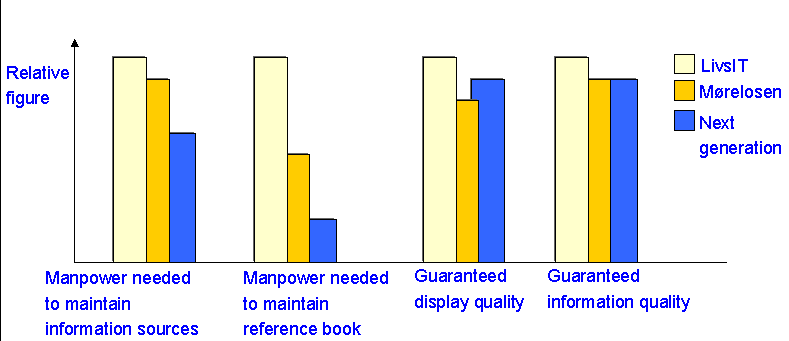
The main trend is that by using new technology we can make services of very high quality, but by using less
manpower maintaining the systems. Since the solutions are based on code and concepts from each other it is actually
hard to give a separate and informative development cost of the tree solutions
Conclusion
The pilot users of both LivsIT and Mørelosen are very enthusiastic, and they do like their electronic
reference book. They have experienced that the responsibility of the information supplier is very important to
clarify and that the information should be quality checked to avoid errors of different kinds. There have also
been minor technical start-up problems.
The projects and technical solutions described in this paper represent an ambition to develop concepts and technical
solutions that use Internet not only for representing static public information, but also dynamic and customised
public information adjusted to the actual needs of the citizen. In Norway, and as far as we now also in other countries,
the Internet has become an important channel for public information. But it is a problem that these Internet based
information services seldom is customised and adjusted to the users need. In this respect LivsIT and Mørelosen
represent attempts towards more user friendly and adjusted services.
The projects have a solid political and organisational foundation in Norway with political and financial support
from both central, regional and local government bodies. Nevertheless, a major challenge in further work is how
to ensure commitment and co-operation in these projects from the largest central agencies which also are the most
important information suppliers, e.g. the agencies for tax, labour and national public insurance. Another challenge
is to develop technical solutions that do not demand heavy investments and resources from the users in the municipalities
and counties. The two projects have had special focus on reuse of the information already available on Internet.
And we believe that reuse of existing and multiple use of the same information is a correct way to go. When the
Norwegian Central Information Service has published its 3000 brochures then both LivsIT and Mørelosen can
use the same information sources as a part of their service.
In the paper we have presented and discussed different technological models, their potential and mentioned the
main problems we have had in the projects.
Links